





On August 2, 2023, Reddit—the self-proclaimed “front page of the internet”—experienced a service outage that impacted many of the site’s logged-in users. Unfortunately for the popular web forum, the outage occurred on the heels of API changes that many in the community viewed as controversial. While the outage didn’t grab as many headlines as the API changes, we can still learn something as we examine the incident.
In this post, we’ll use Reddit’s lightweight incident report and other sources to explore what happened. We’ll also provide three essential tips you can take away from the incident to improve your infrastructure monitoring and incident response.
Scope of the outage
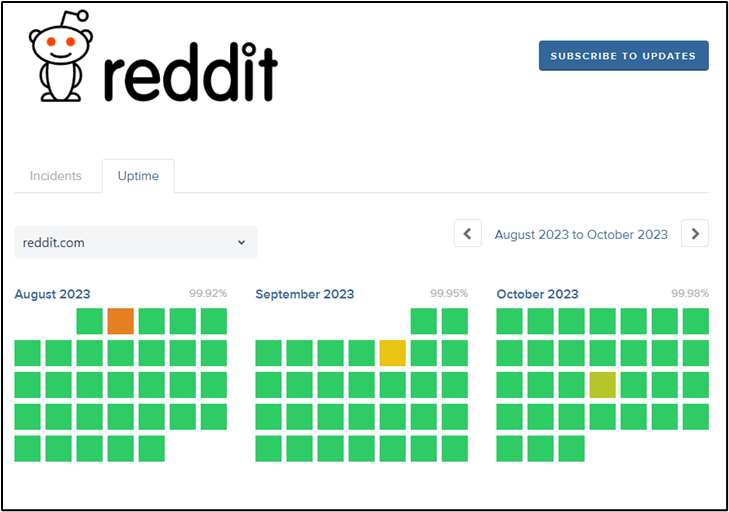
The Reddit service status page for August-October 2023. (Source)
According to its incident report, Reddit began investigating the incident at 13:58 PDT on August 2, 2023. It was marked resolved at 15:15 PDT the same day. Per Reddit’s status page for August 2023, the outage affected the desktop web app, mobile web app, and native mobile app. The vote processing, comment processing, spam processing, and Modmail services were unaffected.
Reddit has over 50 million daily active users (DAUs), and many authenticated users were affected by the incident. According to The Verge, Downdetector reports for Reddit peaked near 30,000 during the incident. Based on sources such as The Verge article, a Variety post, and tweets around the time of the incident, issues reported during the incident included:
- Blank white screens on page loads
- Many generic “down” reports
- Encountering “Our CDN was unable to reach our servers” error messages
- Services generally work if users are not logged in
What was the root cause of the outage?
“Elevated error rates” are the best pointers to root cause we have available. Of course, that doesn’t tell us precisely what was wrong, and without a detailed post-mortem from the Reddit team, we may never know the technical details. Even the “Our CDN was unable to reach our servers” error is generic enough that it doesn’t give us technical specifics (the same error was reported by Reddit users three years ago).
However, we can examine the information we know and think through possible root causes for similar issues. Frankly, this approach can be even more effective for teams looking to improve their availability and address potential gaps in their infrastructure and processes.
According to Himalayas, the Reddit tech stack includes a wide range of components such as:
- Node.js: A cross-platform JavaScript runtime.
- Amazon EC2: Compute nodes on the AWS platform.
- Google Compute Engine: Virtual machines on the Google Cloud Platform (GCP).
- Nginx: A web server, load balancer, and reverse proxy.
- Kubernetes: A container orchestration platform.
- Redis: An in-memory datastore often used for caching, as a database, or as a message broker.
- Hadoop: A distributed computing framework.
- PostgreSQL: A popular relational database management system.
- Amazon Route 53:The AWS DNS service.
- Pingdom: A website monitoring service we think you might like.
- Fastly: A content delivery network (CDN).
And that’s far from an exhaustive list of Reddit’s tech stack components! Simply looking at this list, we can generate some ideas of what could create “elevated error rates”. For example, perhaps there was a configuration issue between the CDN (Fastly) and backend compute nodes running Ngnix as the origin servers. Perhaps some Kubernetes pods were failing and not restarting due to misconfigured liveness or readiness probes.
Alternatively, a Route 53 tweak could lead to another instance of “it’s always DNS.” Viewing the problem differently, since authenticated users seemed to have experienced issues, an underlying problem with the databases and services used to support identity management could have caused issues.
What can we learn from the Reddit August 2023 outage?
Like any outage, one of the most important questions is: What can we learn? Many of the best lessons in tech come through learning from failures. The Reddit outage is another great opportunity to identify key takeaways that can be applied to our projects. Below are our three biggest takeaways from this incident:
Takeaway #1: Do the preparation work it takes to act fast
Reddit has had several headline-grabbing incidents in recent years. Fortunately for the massive online forum, this one wasn’t a hot topic for too long. That was in large part because Reddit solved it quickly.
The ability to solve incidents quickly depends mainly on preparation. So, if you’re only acting fast after an incident begins, you’re already too late. Being “fast” when it matters depends on:
- Effective monitoring: You should know about issues before your users do. The right instrumentation and tooling for effective observability can go a long way here.
- Automation: Ideally, you’ll want to automate recovery from as many scenarios as practical. High availability and failover technologies, such as advanced load balancing with Ngnix, can help teams automate recovery when it counts.
- A fast-acting incident response team: Try as we might, not everything can be automated. If no one is available to handle an incident and the solution isn’t automated, it isn’t going to be resolved. Your incident response team can make or break your incident response times.
- Well-tuned alerts: Alert fatigue is a real problem for incident responders. With so many different systems to monitor, and each one capable of sending alerts, knowing what really matters at any given moment can be challenging. Fine-tuning alerts to ensure you set suitable notification thresholds can reduce cognitive load and make it easier for incident responders to do their jobs.
- Plans: Incident response plans, backup and recovery plans, and even playbooks are all examples of plans and processes you should have before an incident. With these in place, you’ll have a guiding light during the chaos. Without them, your incident responders will be left scrambling.
Takeaway #2: Ping isn’t always enough
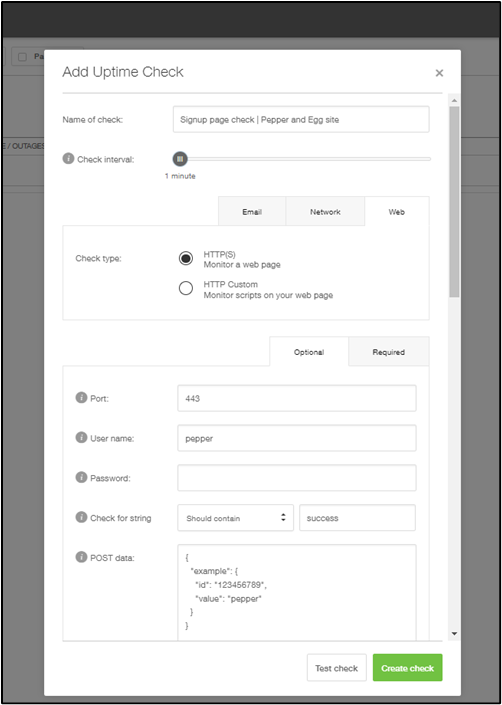
An HTTPS check in Pingdom.
In this incident, service was down, but the site wasn’t completely unresponsive. This type of failure mode isn’t exclusive to distributed web apps. Individual servers and even IoT devices can fail similarly, and one of the most common symptoms is ping responding while other services fail.
For very small sites and teams, basic ping monitoring is something, but it isn’t going to catch issues like this. That’s where more advanced service checks, such as checking HTTPS services, come into play. Checking the status of a specific service goes a step further than ping and can help clarify health at the application layer.
Takeaway #3: Consider user journeys
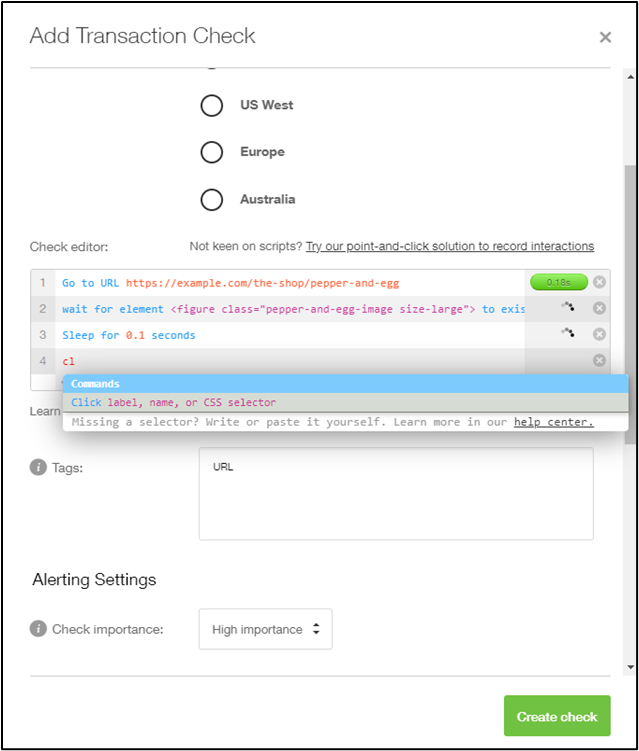
Creation of a transaction check in Pingdom.
With the complexity of modern web applications, even simple application-layer checks might not be enough. User journeys often involve multiple steps that interact with various underlying services. Technically, we can treat these different journeys as transactions we can monitor.
Monitoring transactions helps teams catch those nuanced issues that can easily slip through the cracks with simple service monitoring. For example, in Reddit’s case, monitoring a transaction to log in and view a page would likely have generated an alert for their incident response team during the August 2023 outage.
Transaction monitoring also helps to keep monitoring user-focused, which can be challenging when there are so many moving parts. For example, in Pingdom, transaction monitoring for a user journey that involves filling out a web form may be constructed with these steps:
- Go to a specific URL
- Authenticate
- Click selections based on an element
- Click a submit button based on an element
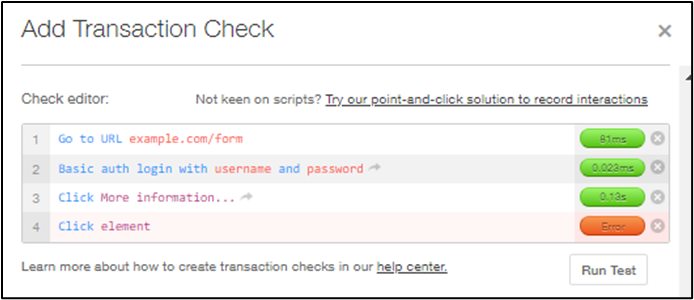
Creating a basic transaction check for a webform in Pingdom.
If that end-to-end transaction works, then all the underlying services are doing what they need to. If it doesn’t, then we can drill down further armed with knowledge of where the user journey is breaking.
How Pingdom can help
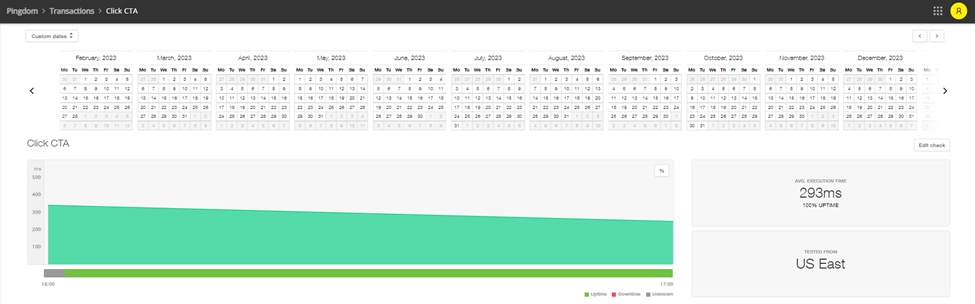
A dashboard displaying metrics for a transaction check in Pingdom.
Pingdom® is a simple, end-user experience monitoring platform that enables teams to quickly respond to incidents. Teams can use Pingdom to monitor services from over 100 locations, communicate to users with a public-facing status page, and implement synthetic and real-user monitoring (RUM).
Teams can also create detailed checks based on transactions that mimic user journeys in a web application. In addition to building the checks based on web elements yourself, Pingdom offers a transaction recorder that reduces the technical knowledge required to create complex checks.
To try Pingdom for yourself, claim your free 30-day trial today!


