





One of Meta’s biggest assets, Instagram, experienced an outage on May 21, 2023, that left users unable to access the social media platform. While outages are never ideal, the social media giant reacted quickly and restored service in about two hours.
Limited details have been made available regarding the underlying cause of the outage. However, there’s still plenty to discuss and learn from the incident. In this post, we’ll examine what happened and what you can learn from the outage.
Scope of the outage
Much of the data around the outage came from users reporting availability issues on social media and website availability trackers. The Verge reported on the outage, receiving correspondence from a Meta spokesperson. The outage started just after 6:00 p.m. ET and ended around 7:30 p.m. Instagram Comms tweeted at 8:19 p.m. ET to confirm the outage was over.
The Verge cited over 175,000 user reports during the peak of the outage. With over 2 billion monthly Instagram users worldwide, the outage likely impacted significantly more people than those that reported issues.
What was the root cause of the outage?
Meta is well known for sharing about their engineering efforts, often on their public-facing engineering site. It has even posted about the causes of outages, such as when they cited a router configuration change as the cause of a 2021 outage. However, the cause of the Instagram outage in May of 2023 was described simply as a “technical issue.”
That means we can rule out root causes such as DDoS attacks. And the fact other Meta services weren’t affected—as was the case when Facebook, Instagram, and WhatsApp were all simultaneously down in 2021—implies the issue wasn’t related to a large data center or network backbone that may have impacted other Meta services too.
Unfortunately, we don’t have a detailed analysis to lean on as we did with the Roblox Halloween outage, so we can’t derive a root cause after eliminating those possibilities.
Instead, let’s look at the Instagram tech stack to understand (in theory) what might have gone wrong.
The Instagram architecture and tech stack
In a world where serverless and microservices get a lot of attention, Instagram and Facebook buck that trend with an architecture that HAMY Labs describes as “service-based monoliths.” In short, Instagram uses a monolith for its core app logic and discrete services for specialized workloads like machine learning and video encoding.
Given that Instagram publishes more data—in one day—than what’s contained in the Library of Congress, we have compelling evidence that Instagram’s monoliths can scale. This also means there is probably some risk of the core app logic breaking in a way that causes a large-scale service disruption. Instagram uses a Python and Django-based tech stack to build its core application. So, many common web app issues—such as an incorrect path in a Django URL pattern or an incorrectly defined variable class—could lead to a service disruption.
What can you learn from the outage?
While we can’t say what specifically caused this Instagram outage, the incident does help us reinforce some important lessons in observability. Let’s look at our top three takeaways from the incident.
1. Prioritize monitoring of the end-user experience
Given the broad social media response, the Instagram outage clearly impacted end users. Hopefully, user reports weren’t the first way that Instagram heard of the outage. What’s the lesson? Make sure you can detect user-impacting issues before your users need to tell you about them.
Getting this right means knowing what and how to monitor your infrastructure. There is a lot you could monitor. However, regardless of your underlying architecture and tech stack, the end-user experience is what ultimately matters.
Your monitoring and observability strategy should account for where your users are located and how they access your applications. For example, network issues in Europe could create a service outage for all your European users while North American users are unaffected. If you’re only monitoring metrics and uptime from North America, the issue may go undetected until the complaints from Europe start rolling in.
Similarly, users of your website might be unaffected by a bug that breaks the native mobile app. If you’re only monitoring the web app, then you’ll be caught by surprise.
Two key tactics for proactive monitoring with the end-user experience in mind are:
- Real-user monitoring (RUM) provides detailed metrics related to how end users interact with your apps and sites—including active sessions, bounce rate, and page views—along with the ability to filter based on criteria like device type, browser, and location.
- Synthetic monitoring (SM) simulates user interactions on your site so you can know if something breaks before your users do. With SM, you can be notified once a workflow is slow or unresponsive so you can quickly respond and resolve the issue. You can also create reports for users and customers demonstrating compliance with service-level agreements (SLAs).
2. Assume outages will occur
Despite our best efforts, outages happen. Outages occur for tech giants like Instagram and small IT teams alike. While you should design your infrastructure to be as resilient as is reasonable (there is always a point of diminishing returns), contingencies are essential. Therefore, you should set expectations for stakeholders and the teams responsible for maintaining your infrastructure about how you’ll handle the inevitable outage.
Defining an error budget is often overlooked, but it will help to build a culture that proactively accounts for outages. SLAs and service-level objectives (SLOs) should lead to the establishment of an error budget. An error budget defines the maximum time a service can fail without breaching service commitments. Ensure all stakeholders understand this, and then optimize your processes and infrastructure to stay under budget. The power of error budgets is that they foster a realistic approach to reliability, balancing user experience with engineering effort in a way that makes business sense.
3. Communicate when something goes wrong
Uncertainty can frustrate and confuse end users. When a service is down, they might not know if the issue is with their network or your application. A quick check of comments related to outages for platforms like Instagram will remind you of just how true this is. The problem is that when there is a significant outage, teams are often more focused on resolving the issue than on outbound communication.
In addition to outbound communication (like tweets or emails to users), public-facing status pages are a great way to inform your users about an ongoing incident. A status page can display key service metrics and clarify your services’ current status. While outbound communications are still important, status pages give users a source of truth that can remove ambiguity when issues occur.
How Pingdom can help
Pingdom® is a simplified end-user experience monitoring platform that makes it easy to monitor what matters when it comes to user-facing applications. With Pingdom, you can implement synthetic and real-user monitoring from a single pane of glass. With the ability to monitor services from over 100 locations across the globe, you can easily diagnose application performance regardless of your users’ regions. Additionally, Pingdom offers a public status page feature so you can keep your users informed about service availability.
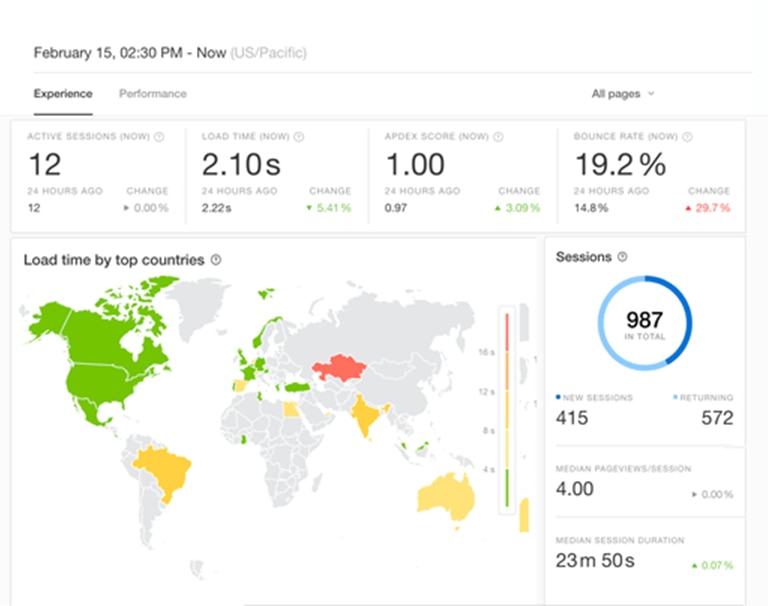
Real-user monitoring (RUM) experience dashboard in Pingdom. (Source)
To try Pingdom for yourself, claim your free 30-day trial today!


